En esta
ocasión, leímos el paper denominado Teaching the SIMD Execution Model: Assembling a Few Parallel Programming Skills
por Ariel Ortiz, publicado en el marco del 34° SIGCSE,
en este se menciona que durante un curso de ensamblador que era ofrecido con anterioridad
en el ITESM CEM, era abordado el tema de programación paralela en arquitecturas
SIMD (Single instruction/Multiple Data).
 |
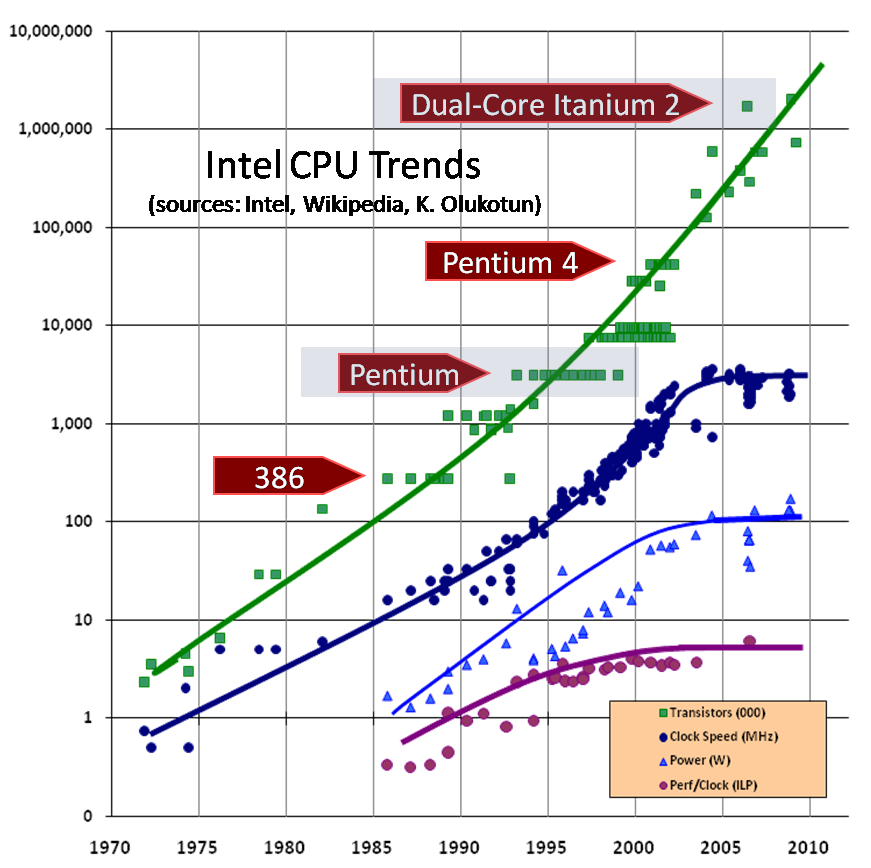
| Comparación de arquitecturas |
Este paper trata un tema bastante interesante, y que jamás
había escuchado; a partir de la década de los 90, los procesadores contienen en
su arquitectura registros de 64 y 128 bits (dependiendo de su tecnología), lo
que se denominó MMX y SSE/2. La verdad es que esto cambia las cosas, ya que
permite realizar programación “paralela” en un solo núcleo. ¿Sus desventajas?
Hay que programar a bajo nivel, y es posible que algunos compiladores no lo
soporten.
Y cuando digo que es necesario programar a bajo nivel,
me refiero a que este conjunto de instrucciones SIMD especializadas son
aprovechadas en mayor medida al usar… Ensamblador. Aunque existen algunas
librerías, como la usada en clase, que permite aprovechar esta capacidad a
través de C.
Este modelo de programación paralela mononucleo, que
aun puede ser extendida para aprovechar verdaderamente el 100% del potencial de
los procesadores modernos, es como sigue:
- Cargar diferentes variables (de memoria principal), regularmente de un arreglo, en un registro de 128-bits (el numero de variables dependerá del tamaño de ellas)
- Aplicar una operación a los dos registros de 128-bits, el resultado será un registro de 128-bits (donde las variables individuales que representan resultados independientes).
- Si es necesario, cargar de nuevo el valor a memoria principal (separando de nuevo las variables)
Como podemos ver, estas operaciones son mas útiles cuando
queremos aplicar una misma operación a diferentes variables (dentro de un
arreglo), por ejemplo, sumarle “dos” a cada registro. De esta forma (y
dependiendo del tamaño de las variables), podemos modificar concurrentemente 4,
8, 16, etc. registros en una sola operación a nivel procesador.
Por esta razón, esta técnica tiene un uso más
extendido en procesamiento audiovisual, grafico, matemático, y compresión donde
el tiempo es vital.